AI Coding, From Idea to Achievement
什么是 Ralph
https://github.com/snarktank/ralph

在 Claude Code 以及 LLM Model 的快速发展下,Geoffrey Huntley 发现 Claude Code、Gemini CLI 等 AI 编程工具有一个结构性缺陷,即上下文窗口越用越满,LLM 在长会话后期质量明显下降,写出来的代码越来越差,还容易"忘记"之前的约定。解法不是更大的上下文,而是根本不让上下文积累,把大任务拆成小 story,每次只给 AI 做一件事,做完易开,状态靠文件传递。
这个模式以《辛普森一家》里的 Ralph Wiggum 命名,那个永远忘记上节课内容,但每次都能完成眼前简单任务的小孩。
因此,他们在 Claude Code 外面嵌套了一层循环的 bash 脚本,核心就是 ralph.sh。
Ralph 工作原理
while 还有未完成的 story:
启动一个全新的 Claude Code 实例
把 CLAUDE.md 作为 prompt 喂给它
Claude Code 工作(读代码、写代码、运行命令)
Claude Code 退出(上下文清空)
下一次迭代重新开始
Ralph vs 普通 Claude Code 的核心区别
| 普通 Claude Code | Ralph | |
|---|---|---|
| 上下文 | 单次会话,越写越满,最终截断 | 每次迭代全新实例,上下文永远干净 |
| 记忆 | 靠上下文窗口 | 靠 progress.txt + prd.json + git history |
| 任务管理 | 你盯着 | prd.json 自动追踪哪些完成了 |
| 停止条件 | 你说停 | 所有 story passes: true 自动退出 |
| 适合任务 | 对话式、探索性 | 多步骤、机械性、可拆分的实现任务 |
Ralph 并不算一个新的技术,而是一个对于 Claude Code 写的任务循环,价值在于这个设计思路,把"长任务"分解成"多个短任务",用文件系统做记忆,让 AI 保持在最佳工作状态。
如何上手 Ralph
Option 1, Copy to your project
把 ralph 的文件复制到你的项目
# From your project root
mkdir -p scripts/ralph
cp /path/to/ralph/ralph.sh scripts/ralph/
# Copy the prompt template for your AI tool of choice:
cp /path/to/ralph/prompt.md scripts/ralph/prompt.md # For Amp
# OR
cp /path/to/ralph/CLAUDE.md scripts/ralph/CLAUDE.md # For Claude Code
chmod +x scripts/ralph/ralph.sh
Option 2, Install skills globally (Amp)
把 skills 拷贝到 Amp 或 Claude 的配置目录,跨项目可用。
For AMP
cp -r skills/prd ~/.config/amp/skills/
cp -r skills/ralph ~/.config/amp/skills/
For Claude Code (manual)
cp -r skills/prd ~/.claude/skills/
cp -r skills/ralph ~/.claude/skills/
Option 3, Use as Claude Code Marketplace
添加 Ralph marketplace 到 Claude Code
/plugin marketplace add snarktank/ralph
然后安装 skills
/plugin install ralph-skills@ralph-marketplace
安装后可用的 skills
/prdGenerate Product Requirements Documents/ralphConvert PRDs to prd.json format
当你让 Claude 做以下事情时,这些 skills 会被自动调用
- "create a prd", "write prd for", "plan this feature"
- "convert this prd", "turn into ralph format", "create prd.json"
配合 Superpower 使用 Ralph 完成一个案例
背景需求,我们使用高斯计算经常需要从输出的 log 文件里提取能量、零点能、虚频等信息,虽然有部分软件或者工具可以实现,但我们通过 Ralph 来实现这样一个小的需求,制作一个工具来自动化提取这些信息。
在盛子瑞分享的 Skills 中详细介绍了如何应用 Superpower,这里不多赘述,可以从他的那篇博客中直接学习 Skills 时代对 Agent 的进阶应用。
Workflow
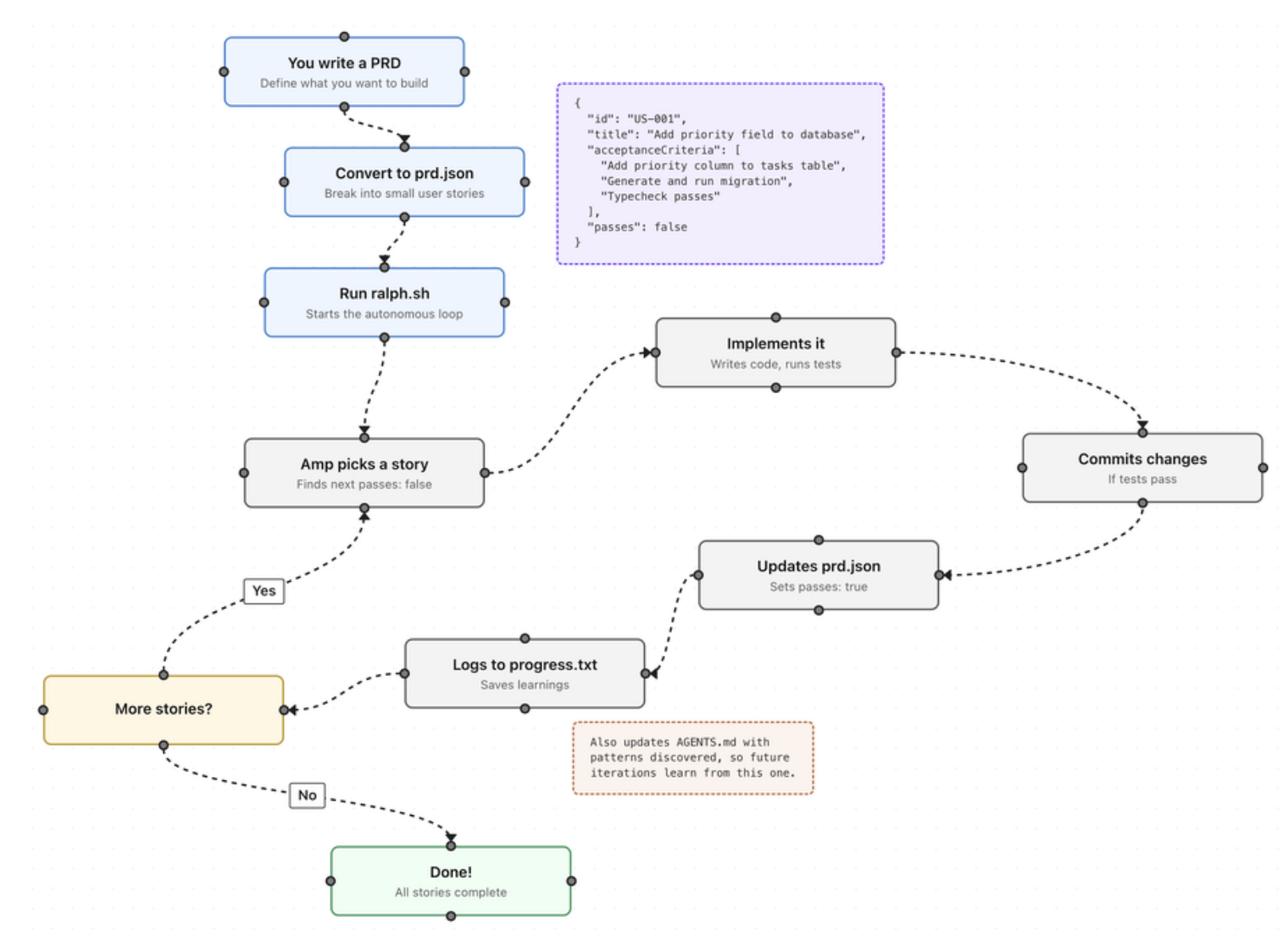
整个管线如下
你(描述需求)
|
▼
Superpowers(对话式需求分析)
输出, 设计文档 + prd.json(任务列表)
|
▼
Ralph(自动编程循环)
读取 prd.json → 调用 Claude Code → 实现 → 验证 → 标记完成 → 循环
|
▼
可运行的代码 + progress.txt(迭代日志)+ cost_log.txt(费用记录)
我们要特别提出的是,Superpower 强大的设计能力与从 Idea 变为文档的能力,正是我们 PRD 需求文件所需要的。它可以很好地帮助我们理清需求,并转化为文档。
1. Superpower 的使用过程
在该案例中,我一开始仅表达了我需要做一个小的 Live coding 工具
对话过程
Q, 做什么领域的工具? → A, 理论化学计算
Q, 什么类型的工具? → A, 批量解析 + 出图
Q, 解析哪种输出格式? → A, Gaussian .log 文件
我们需要的输出为
- 设计文档
- 项目名,
chem-report, Gaussian 输出批量解析工具 - 架构, 单文件 Python CLI,三个子命令,依赖仅 matplotlib
- 三个功能模块(US-001 解析、US-002 批量 CSV、US-003 画图)
- 技术规范, SCF 能量取最后一个
SCF Done行、虚频统计负值、Normal termination判断收敛 - 转化后的 prd.json(ralph 任务的衔接)
{
"project": "chem-report",
"userStories": [
{
"id": "US-001",
"title": "解析单个 Gaussian log 文件",
"acceptanceCriteria": [
"从 .log 文件提取 SCF 最终能量(最后一个 'SCF Done' 行的值)",
"统计虚频数量('Frequencies --' 行中所有负值的个数)",
"python chem_report.py parse sample_data/mol_A.log 可正常运行"
],
"priority": 1,
"passes": false
},
{
"id": "US-002", "title": "批量扫描目录,生成 CSV 汇总",
"passes": false
},
{
"id": "US-003", "title": "画能量对比柱状图",
"passes": false
}
]
}
2. Ralph 工具的使用
运行 Ralph 需要的输入文件
prd.json, 结构化的任务列表(Superpowers 生成)CLAUDE.md, 给 Claude Code 的指令(告诉它如何工作)sample_data/, 3 个示例 Gaussian log 文件用于验证ralph.sh, 自动化循环脚本
./ralph.sh --tool claude 5 # 在你终端直接跑
# 如果任务需要大量资源,把 ralph.sh 提交到集群
提交后我们得到了如下 progress.txt 的摘要
# Codebase Patterns
- Single file project: all logic in `chem_report.py`
- Use `python3` (not `python`) to run scripts on this system
- SCF energy: last match of r'SCF Done:.*?=\s+([-\d.]+)'
- Imaginary freq count: scan `Frequencies --` lines, count negative floats
- CSV written to current working directory (not sample_data/)
- matplotlib.use('Agg') required before importing pyplot
## 2026-04-17 - US-001, US-002, US-003
- Implemented all three user stories in a single `chem_report.py`
- US-001: parse subcommand - extracts SCF energy, ZPE, n_imaginary, converged
- US-002: batch subcommand - scans directory *.log, writes results.csv
- US-003: plot subcommand - reads results.csv, saves energy_comparison.png
with colored bars
- Files created: `chem_report.py`, `results.csv`, `energy_comparison.png`
- Learnings:
- python not found; use python3
- mol_B.log has one imaginary frequency (-234.5678)
- All three sample files show Normal termination (all converged=True)
- WARN status triggered for mol_B due to imaginary frequency
prd.json 中所有 story 的状态也改为了 true,意味着全部任务完成。
{"id": "US-001", "passes": true},
{"id": "US-002", "passes": true},
{"id": "US-003", "passes": true}
检查所得到的工具的效果
解析单个文件
$ python3 chem_report.py parse sample_data/mol_A.log
filename energy(Ha) ZPE(Ha) n_imag converged
---------------------------------------------------------------------
mol_A.log -115.731052 0.054050 0 True
$ python3 chem_report.py parse sample_data/mol_B.log
filename energy(Ha) ZPE(Ha) n_imag converged
---------------------------------------------------------------------
mol_B.log -78.587891 0.051234 1 True
$ python3 chem_report.py parse sample_data/mol_C.log
filename energy(Ha) ZPE(Ha) n_imag converged
---------------------------------------------------------------------
mol_C.log -76.418502 0.020912 0 True
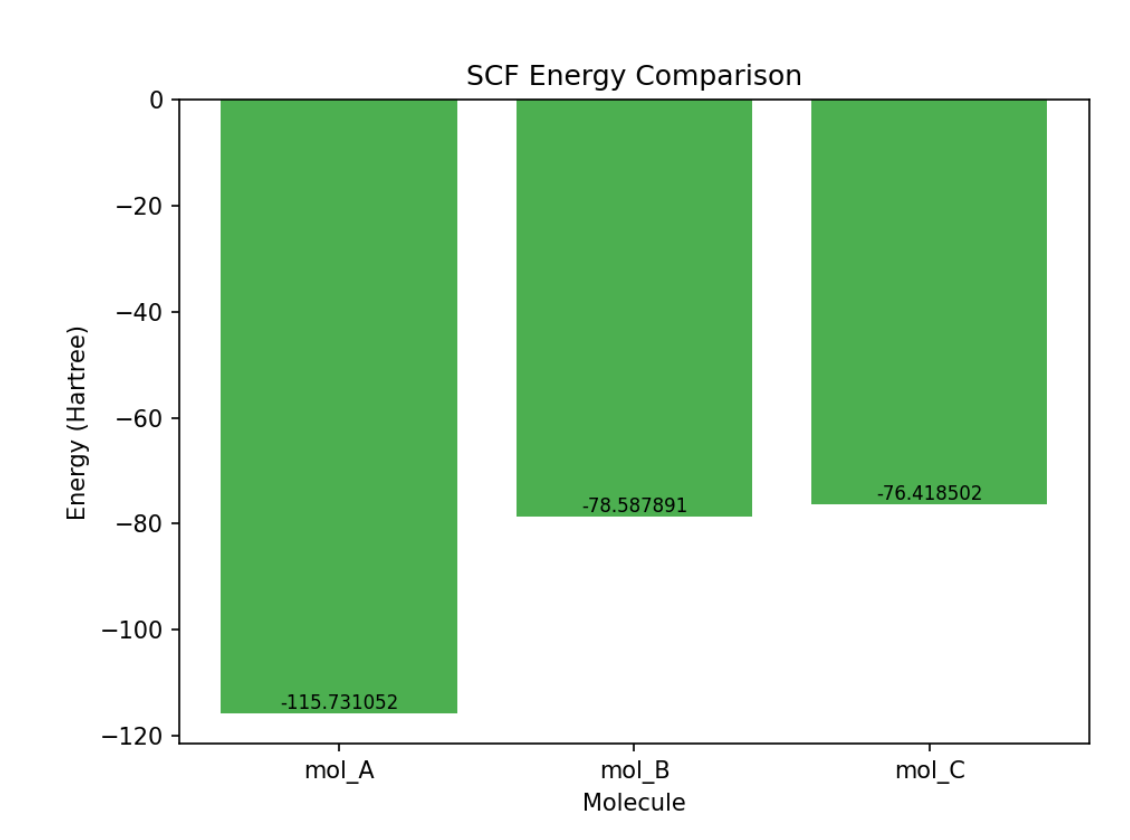
mol_B(乙烯)有 1 个虚频,为过渡态结构。
批量扫描 → CSV
$ python3 chem_report.py batch sample_data/
mol_A.log OK
mol_B.log WARN
mol_C.log OK
Wrote 3 rows to results.csv
生成的 results.csv
filename,energy_hartree,zpe_hartree,n_imaginary,converged
mol_A.log,-115.731052348,0.05405,0,True
mol_B.log,-78.587891234,0.051234,1,True
mol_C.log,-76.418502134,0.020912,0,True
能量对比图
$ python3 chem_report.py plot sample_data/
Saved energy_comparison.png
监控 Token 用量, 在你的需求中可以提到你需要监控 token 的使用量
| 迭代 | 完成内容 | 总费用 | 耗时 | Claude 对话轮数 |
|---|---|---|---|---|
| 1 | US-001 + US-002 + US-003(全部) | $0.3666 | 95 秒 | 17 轮 |
对于 Ralph 工具使用的心得与经验
1. Ralph 的后台与模型设置
Ralph 调用的后台可以是 Amp 或 Claude Code,我仅使用过 Claude Code,在 run 的时候需要 --tool claude 指定使用 CC。调用的模型则会是你 .bashrc 或 .bash_profile 所设置的默认 CC 的模型,即如下这个 model 设置。
# AIHUBMIX_API_KEY 替换为你从 AIHUBMIX 平台获取的 Key
echo 'export ANTHROPIC_BASE_URL="https://aihubmix.com"' >> ~/.bash_profile
echo 'export ANTHROPIC_AUTH_TOKEN="AIHUBMIX_API_KEY"' >> ~/.bash_profile
echo 'export ANTHROPIC_MODEL="claude-sonnet-4-5"' >> ~/.bash_profile
2. 可以让 AI 总结 AI 完成的工作,但不要盲目地相信
AI 编程工具会在短时间内产生让人无法一句句去评估的代码量,你不太可能有精力逐个文件逐行的检查 AI 写的代码。这个时候开启该工作文件夹的对话框 @工作文件夹,让 AI 总结结果是最省事的办法。但一般来说,得到回应中,Ralph 的输出结果会是非常正面的。对于大部分任务而言,在多次的迭代后,几乎所有的 user story 都会显示 pass,这可能是真的全都写得非常好,都满足了需求,也可以是 AI 无法完成,但为了让你的需求通过而写的空壳。通过你的测试,你会发现效果并不如意。因此,当 Ralph 完成后,你可以通过 AI 总结一下目前的结果,但也需要实实在在的测试来验收。
3. 在 AI 编程工具运行过程中就难免遇到幻觉、能力边界问题
我的经验来说,详细的需求文档(包括 prd.json)是保证任务可以大部分完成的基础,通过 Superpower 和 ralph 的 prd skill 其实可以把你的需求很好地变为让 ralph 的输入文件。如何细分你需求的模块以及哪部分涉及了理论、专业知识,则需要你提供给大模型来完成,尽量不让它做随机的探索。太难太大的任务,他会绕开核心问题,为了通过 prd 的需求测试,他会偷懒。
4. Ralph 破破烂烂,我们缝缝补补
我们并不能奢求一次 Superpower 产生的需求文档和单次的 Ralph 能让某个科研课题从 Idea 到直接的落地。根据你的理想要求、测试结果,对 AI 编程产生的代码功能进行修补是很必要的,多次的提需求和测试,总能在最后很好地实现你的需求,因此需要耐心的"debug",可能修补的是上一轮迭代没有完成的内容,可能修补的是过去还并不清晰的需求。
推荐几个可以尝试的全自动工作流工具
1. Deepwiki
github 仓库的 AI 百科,高效地理解某个库如何运作。
2. AutoResearchClaw
https://github.com/aiming-lab/AutoResearchClaw
AutoResearchClaw 是一个"给一个研究想法,输出一篇可投稿论文"的全自动科研 pipeline。
核心能力
- 输入, 一句研究方向描述
- 输出, 文献综述 + 实验代码 + 结果分析 + LaTeX 论文(NeurIPS/ICML/ICLR 模板)
8 个阶段,23 个步骤
Phase 1 Scoping 问题形式化、研究问题拆解
Phase 2 Literature 多源文献检索(OpenAlex / Semantic Scholar / arXiv)
Phase 3 Synthesis 知识图谱 + Gap 识别 + 假设生成(多 Agent 辩论)
Phase 4 Design 硬件感知的实验设计与代码生成
Phase 5 Execution 沙箱执行,自动修复报错(self-healing)
Phase 6 Analysis 多 Agent 结果解读,决定是否补充实验
Phase 7 Writing 逐节撰写论文
Phase 8 Finalization 质量门控 + 知识归档 + 输出投稿包
几个技术亮点
- 四层引用验证, 专门对抗 LLM 幻觉引用,所有参考文献多源交叉核实
- 硬件自适应, 自动检测 CUDA / MPS / CPU,按算力调整实验规模
- 六档干预模式, 从"全自动"到"每步确认",三个关键节点设有人工审核门
- 知识库时衰减机制, 从历史 run 中提取经验,越旧的经验权重越低
3. AI Paper Writing skill
Academic-paper-skills
- 描述, 系统化的学术论文规划和写作框架
- 特点
- ✅ 双技能工作流 (Strategist + Composer)
- ✅ 7 维度审稿人模拟系统
- ✅ 质量检查点 (3 validation gates)
- ✅ 支持 PhilArchive、arXiv 等预印本平台
- ✅ 包含 Python 验证脚本
- 适用场景, 哲学、跨学科、人文社科类学术论文
- 适配度, ★★★★ (可适配商业伦理、管理哲学等方向)
核心工作流
Strategist(规划),
Phase 1, 平台分析 → 目标期刊 + 风格指南
Phase 2, 理论框架 → 文献 + 研究缺口分析
Phase 3, 大纲优化 → 审稿人评估大纲
Composer(写作),
Phase 1, 基础搭建 → 风格指南 + 章节规划
Phase 2, 系统写作 → 带质量检查的草稿
Phase 3, 润色 → 最终评估 + 投稿准备
claude-scientific-skills/scientific-writing