从 RAG 到 LLM Wiki,让知识不再每次从零开始
资料来源:
RAG 基础讲解:CSDN 博客
背景(问题)
LLM 的能力来自训练阶段学到的参数知识,但这类知识有几个问题:
知识过期
模型训练完成后,后续的新论文、新工具、新项目状态,它默认不知道。
专业知识不足
通用模型知道很多通识,但对你自己的课题、实验记录、代码库、内部文档、前几次分享会内容并不了解。
幻觉与不可验证
它可能生成听起来很合理但没有来源的答案
所以早期大家自然会想:如果 LLM 本身不知道,那能不能让它"先查资料,再回答"?
这就进入了 RAG。
RAG:企业落地大模型的标准配置(方法)
RAG,全称 Retrieval-Augmented Generation,意思是检索增强生成。
不要让 LLM 只凭记忆回答,而是在回答前先从外部知识库里找相关资料,再把资料塞进 prompt,让模型基于资料回答。
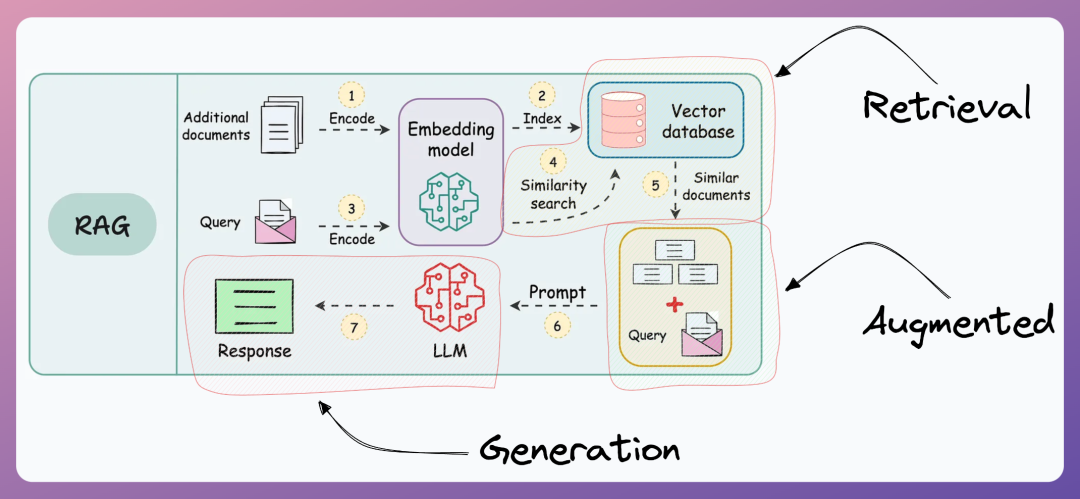
检索(Retrieval):主动"找知识"而非"记知识" 。
传统大模型的知识局限于训练数据,想了解新信息、公司内部文档等,根本无从下手。而 RAG 会主动从外部知识库中,通过近似最近邻搜索(ANN)算法,精准定位与用户问题相关的知识片段。相当于给大模型配了一个"实时搜索引擎",随时能调取最新、最专属的知识。
增强(Augmented):动态扩展上下文,零成本更新知识。
检索到的知识不会直接给用户,而是先"喂"给大模型,作为上下文的一部分补充进去。这一步解决了两个问题:一是不用花几百万、几千万重新训练大模型,就能让它掌握新知识;二是规避了大模型上下文窗口有限的问题,只把最相关的知识片段传进去,提升效率。
生成(Generation):基于权威依据,生成可信答案。
大模型结合用户的原始问题和检索到的权威知识,生成最终回复。关键是,它能自动关联知识来源,不仅减少了"胡编乱造"的幻觉问题,还让答案可追溯、可验证。
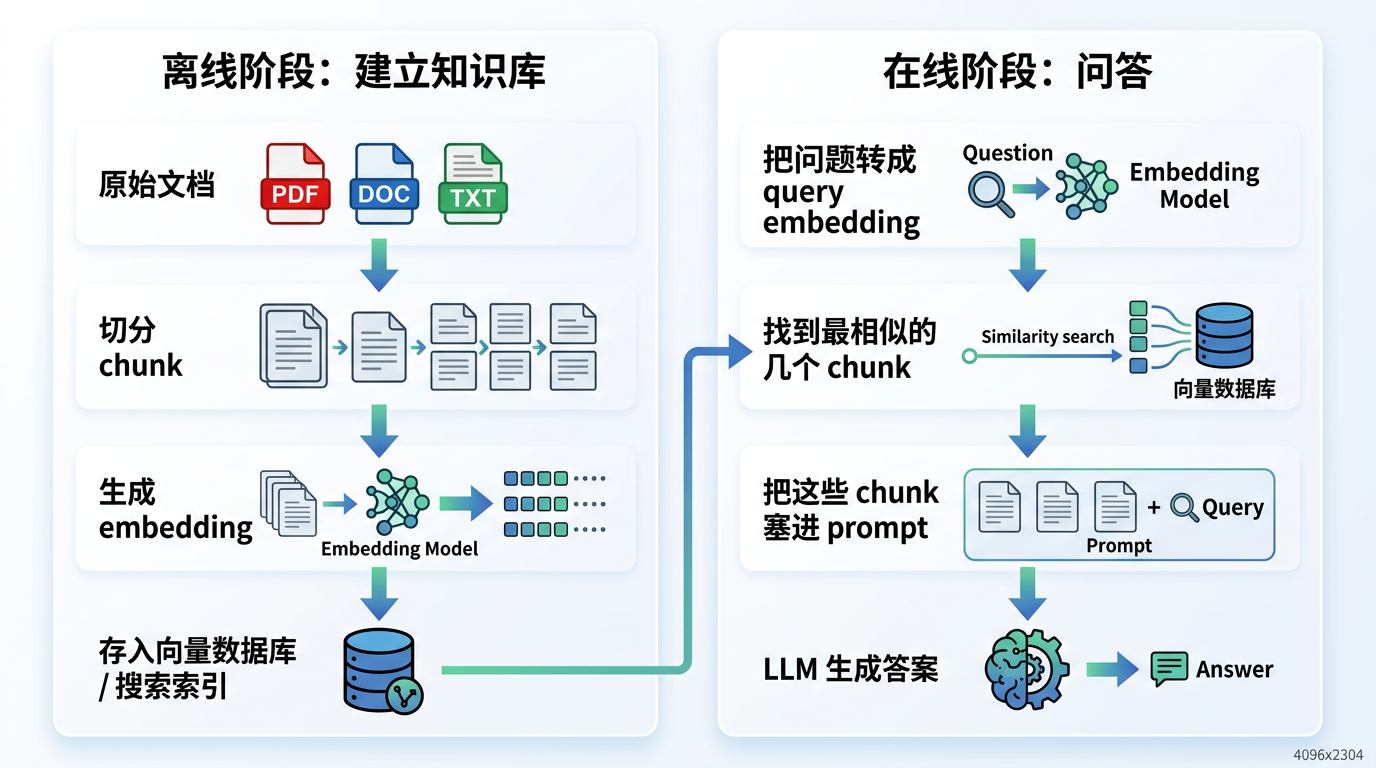
优点
让模型访问私有知识,并且知识可以更新。比如你的实验记录、公司文档、项目会议纪要、代码库说明,这些都不在模型训练集当中,并且相比重新训练模型,更新 RAG 知识库便宜得多。
降低幻觉,方便引用溯源。LLM 的回答可以基于检索到的外部材料,模型不必完全依赖参数记忆,并且可以告诉你答案来自哪些 chunk、哪些文件、哪些页面。
缺点
每次 query 都重新综合
RAG 会重新检索 chunk,重新拼接,重新综合。下次再问类似问题,系统还是重新来一遍。
文档之间没有真正连接
RAG 保存的是"资料碎片",不是"知识结构"。
RAG 的知识库通常是:chunk_001,chunk_002,chunk_003,chunk_004。
而不是:chunk_001→ chunk_002→chunk_003 → chunk_004。
矛盾不会主动暴露,长期研究时没有复利
如果 A 和 B 有矛盾,那么 RAG 只有在某次 query 同时检索到 A 和 B 时,才可能发现矛盾。它不会主动维护一个界面或者概念,也不能"新资料改变旧结论"。
RAG 很适合问一个问题,找一段资料。但是长期研究需要:概念越来越清楚,关系越来越丰富,旧结论不断被修正,新的问题被沉淀,跨文档综合可以复用。

LLM Wiki:从"检索资料"到"编译知识"
核心思想
- Wiki 是一个"持久化、可增长的知识制品"

The wiki is a persistent, compounding artifact.
Persistent:持久化
LLM Wiki 不是一次性的聊天记录, 它会把有价值的信息写成 Markdown 文件,保存在你的文件系统里。
Compounding:复利增长
Wiki 会随着每个 source 和每个 question 变丰富。 LLM Wiki 的增长来自两个入口:新增资料和提出问题。
LLM 不只是临时回答你,如果这个问题很有价值,它可以把答案沉淀为.md 文档。
也就是说,在 LLM Wiki 中,好的问题本身也是知识库增长的动力。
Artifact:知识制品
LLM Wiki 最终产出的不是一次回答,而是一个可以被反复使用、检查、维护、迁移的知识系统。
它可以被人阅读,LLM 阅读,版本控制,搜索重构,扩展,分享。
- 人类负责探索方向,LLM 负责维护结构。

Karpathy 原文里提到,人类通常不会自己写和维护整个 wiki,因为这件事很枯燥,需要总结新资料,更新旧页面,建立交叉引用,发现重复概念,标记矛盾,维护索引,整理页面结构。
人类负责选择资料、提出问题、判断方向、审核重要结论。
Architecture(结构)
- Raw Sources:原始资料层
raw/
papers/
articles/
meeting-notes/
books/
slides/
code-notes/
特点:只读,不可随意修改,作为 source of truth
类似 RAG 里的原始文档库,但区别在于 LLM Wiki 不满足于只索引这些资料,而是要把它们编译进 wiki。
- Wiki:知识页面层
wiki/
concepts/
RAG.md
LLM-Wiki.md
Context-Window.md
Agent-Harness.md
comparisons/
RAG-vs-LLM-Wiki.md
Ralph-vs-LLM-Wiki.md
projects/
AI-Sharing-Series.md
index.md
log.md
- Schema:规则层
Schema 是治理 wiki 的运行方式,包括新增资料时怎么处理概念,页格式是什么,如何写引用等等。
有了 schema,LLM 才像一个有纪律的知识库维护员。
CLAUDE.md
AGENTS.md
wiki-rules.md
templates/
Operation
- Ingest:把新资料编译进 wiki
LLM Wiki 处理新资料时的流程是:新文档 → 阅读→ 提取要点→ 判断涉及哪些旧页面→ 更新旧页面→ 创建新页面→ 添加交叉引用→ 标记矛盾→ 更新整体结构
比如我们已经有一个页面 RAG.md,后来加入 Karpathy 的 LLM Wiki 文章,LLM 不应该只是新增一个 karpathy-article.md,而是在思考:
- 这篇文章是否改变了我们对 RAG 的理解?
- 它是否提出了 RAG 的不足?
- 它是否引出了新的概念:LLM Wiki?
- 它是否需要建立一个 RAG-vs-LLM-Wiki 页面?
所以 LLM Wiki 的 ingest 不是"收纳文件",而是"更新知识结构"。
- Query:不是问 raw docs,而是问已整理的知识结构
用户提问后,LLM 读 index.md,相关概念页,相关比较页,相关 log,必要时回到 raw source 核查,然后生成答案。
如果这次 query 产生了有价值的新综合,可以写回 wiki/comparisons/ 或者 wiki/talks/,问题本身也可以成为知识库增长的一部分。
- Lint:检查知识库健康
定期让 LLM health-check wiki,包括检查页面矛盾、过时 claim、孤立页面、缺失交叉引用和知识空白。
LLM 知识管理系统擅长提出新的研究问题以及寻找新的参考资料。这有助于 wiki 不断发展完善。
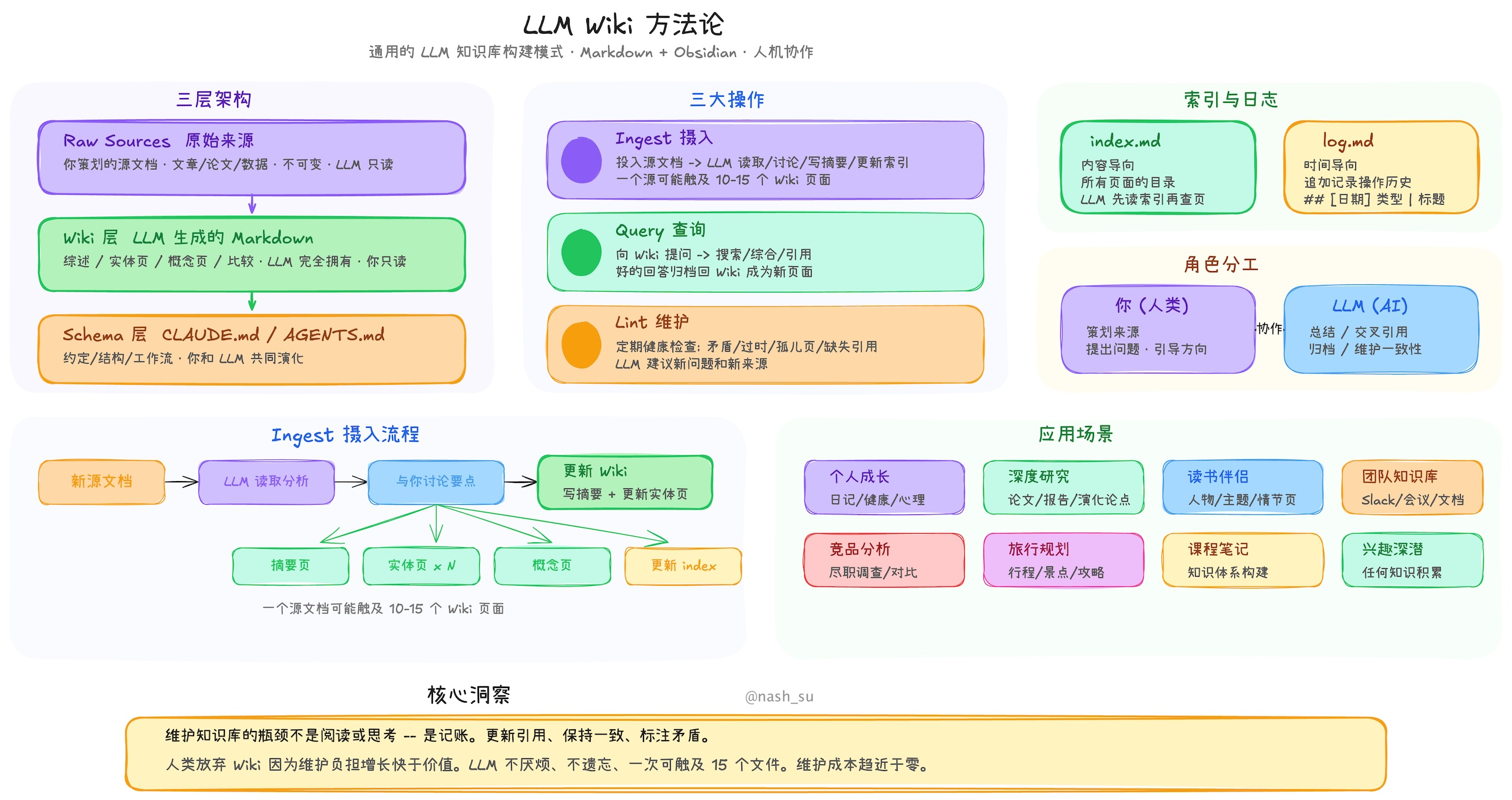
使用 Obsidian
LLM Wiki 很依赖概念之间的连接。Obsidian 对 [[双链]] 的支持正好适合这个需求。
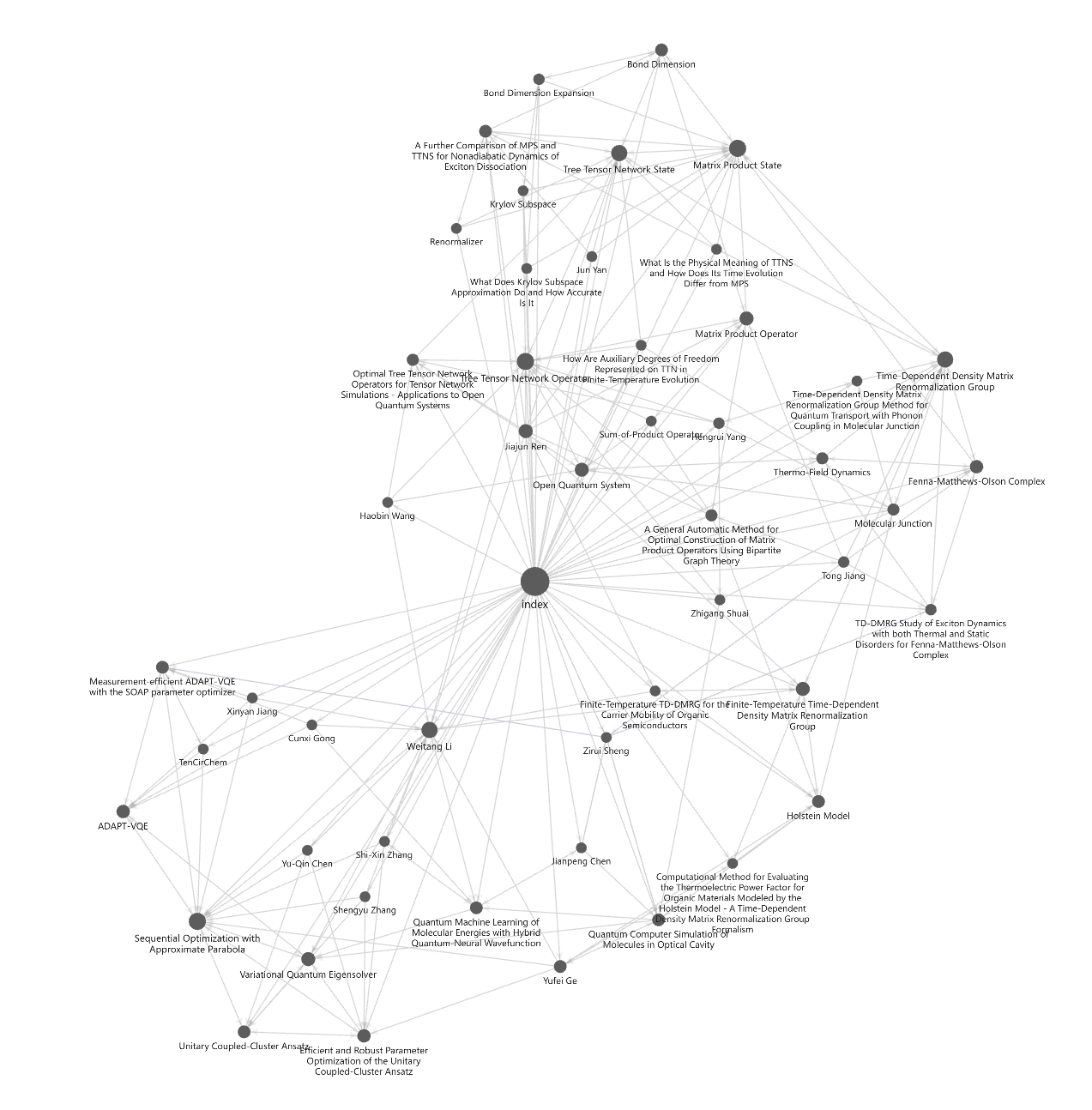
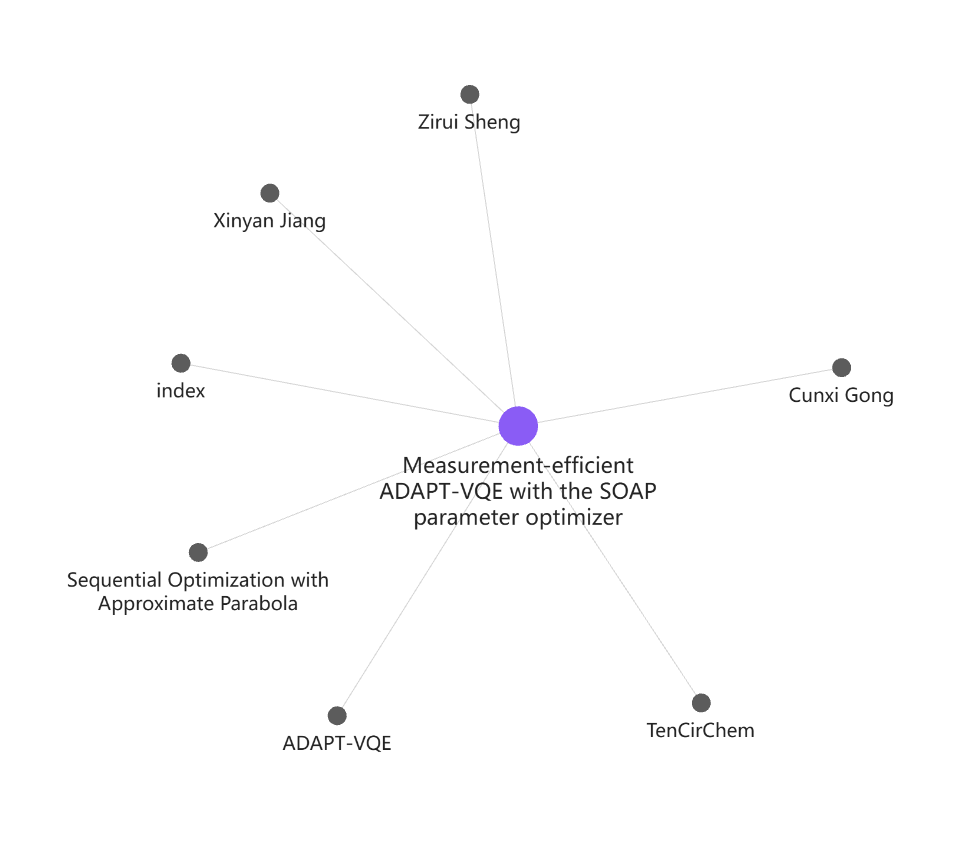
一些缺点
- 维护成本高,需要 Token 支持
- 受 raw 文件影响大,不适合极小规模的情形
- 不能完全替代 RAG,不适合超大规模的情形
- 版本控制要求高,人工介入检查需求高,尤其是初始阶段
- 需要全权让 LLM 控制,人工手动操作会导致错误
快速上手
初始设置
- 安装 Obsidian
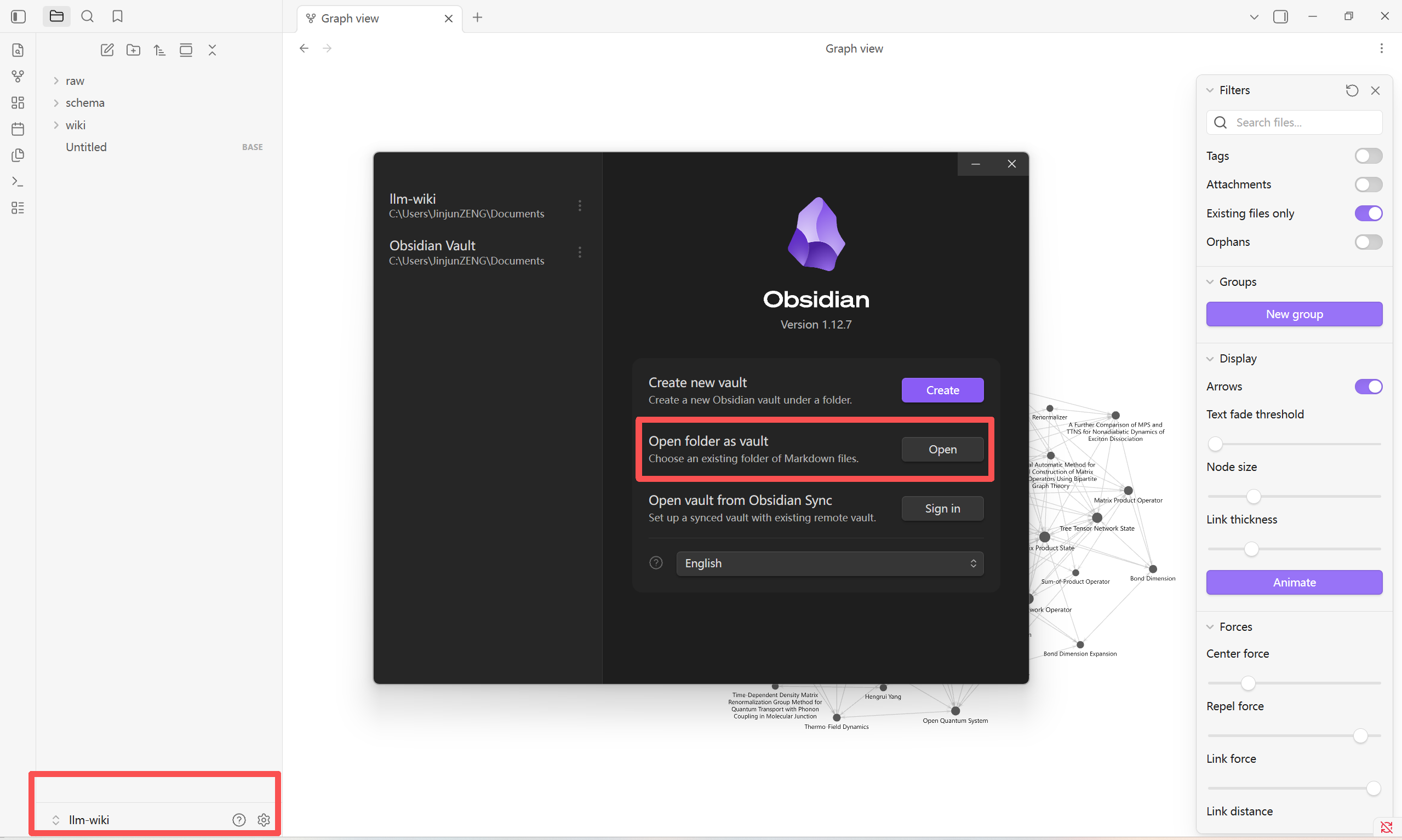
建立一个文件夹 llm-wiki,在安装后选择 Open folder as vault
- 在 Obsidian 左侧文件栏里建这些文件夹:
raw/
├── docs/ # 官方文档、技术手册、论文(PDF/MD格式)
├── prs/ # 代码PR记录、代码评审意见(导出为MD)
├── incidents/ # 故障复盘、问题记录(会议纪要、复盘报告)
├── meetings/ # 会议记录(直接粘贴或导出MD)
├── images/ # 截图、架构图、可视化素材(命名规范:日期_主题.png)
└── others/ # 零散素材(书签导出、笔记碎片、网页剪辑)
wiki/
├── overview.md # 全局概览:Wiki用途、结构说明、核心链接
├── glossary.md # 术语表:领域内核心术语、缩写、释义
├── concepts/ # 概念页:核心概念、原理、对比分析(每个概念一个MD)
├── entities/ # 实体页:人物、工具、产品的详细说明(如Obsidian、GraphRAG)
├── incidents/ # 故障知识页:故障原因、解决方案、预防措施
├── decisions/ # 决策记录页:关键决策的背景、依据、结果
└── links.md # 全局链接索引:所有页面的关联关系
schema/
├── AGENTS.md # AI代理配置:定义各类处理任务的LLM代理及其职责
├── ingest_prompt.md # 摄入提示词:用于LLM处理raw中的原始资料,进行信息提取和初步加工
├── query_prompt.md # 查询提示词:用于LLM根据用户问题从wiki中检索和综合信息
├── lint_prompt.md # 检查提示词:用于LLM验证wiki页面质量、标记矛盾、发现优化点
└── page_template.md # 页面模板:定义wiki中各类页面的标准格式和结构规范
- schema/AGENTS.md 告诉 LLM agent 如何维护 wiki,这里展示一个模板:
# LLM Wiki Maintenance Instructions
You are maintaining a Karpathy-style LLM Wiki.
## Directory roles
- raw/: immutable source materials. Do not edit or delete.
- wiki/: synthesized Markdown knowledge base.
- schema/: rules, templates, and maintenance instructions.
## Writing rules
1. Create Markdown pages under wiki/.
2. Use Obsidian-style links: [[Concept Name]].
3. Every important claim must cite a source filename or URL.
4. Prefer updating existing pages over creating duplicates.
5. Keep pages concise but connected.
6. Add backlinks and related pages.
7. Add "Needs verification" when uncertain.
8. Maintain wiki/index.md as the entry point.
## Page types
Create pages for:
- concepts
- people
- papers
- projects
- decisions
- open questions
## Required page sections
Each wiki page should include:
# Title
## Summary
## Key points
## Sources
## Related pages
## Open questions
## Needs verification
- 放入原始资料,并且建议从少量资料开始一步步累计
raw/papers/attention_is_all_you_need.pdf
raw/notes/my_llm_notes.md
raw/articles/rag_blog.md
- 打开 claude code/codex, 让 LLM agent 生成 Wiki:
请按照 schema/AGENTS.md 的规则维护这个 Karpathy-style LLM Wiki。
请先处理 raw/ 里的所有资料,生成第一版 wiki。
具体要求:
1. 不要修改 raw/ 里的原始文件。
2. 在 wiki/index.md 里创建入口目录。
3. 在 wiki/concepts/ 下创建重要概念页面。
4. 如果资料里提到论文、人物、项目,也分别放到 wiki/papers/、wiki/people/、wiki/projects/。
5. 使用 Obsidian 双链,例如 [[RAG]]、[[Embedding]]。
6. 每个页面必须包含 Sources,注明来源文件。
7. 不确定的内容放到 Needs verification。
8. 生成完成后,列出你创建或更新了哪些文件。
后续维护
- Ingest
设置一个 schema/ingest_prompt.md,写入 ingest 的要求,这里展示一个例子:
# Ingest Prompt
You are ingesting new source materials into a Karpathy-style LLM Wiki.
## Goal
Read new or unprocessed files in `raw/` and update the synthesized knowledge base in `wiki/`.
## Rules
1. Do not modify, delete, or rename files in `raw/`.
2. Create or update Markdown pages only under `wiki/`.
3. Prefer updating existing pages over creating duplicates.
4. Use Obsidian-style internal links: [[Concept Name]].
5. Every important claim must include a source reference.
6. If uncertain, add the claim to "Needs verification".
7. Update `wiki/index.md`.
8. At the end, report:
- Created files
- Updated files
- Skipped files
- Items needing human review
## Page types
Use these folders:
- `wiki/concepts/`
- `wiki/papers/`
- `wiki/people/`
- `wiki/projects/`
- `wiki/questions/`
## Required sections for each page
Each page should include:
# Title
## Summary
## Key points
## Sources
## Related pages
## Open questions
## Needs verification
当加入一定的新材料的时候,在 codex 中命令 LLM:
请按照 schema/ingest_prompt.md 执行一次 Ingest。
- Query
新建 schema/query_prompt.md,写入 query 的要求,这里展示一个例子:
# Query Prompt
You are answering questions using a Karpathy-style LLM Wiki.
## Source priority
1. First use `wiki/`.
2. If needed, verify against `raw/`.
3. If the answer is not supported by either `wiki/` or `raw/`, say that the wiki does not contain enough information.
## Rules
1. Do not invent unsupported facts.
2. Cite relevant wiki pages and raw source files.
3. Mention uncertainty clearly.
4. Suggest related pages using Obsidian-style links.
5. If the question reveals a missing topic, suggest a new page under `wiki/questions/` or `wiki/concepts/`.
## Answer format
Use this structure:
## Answer
Direct answer to the user's question.
## Evidence
- Relevant wiki pages
- Relevant raw sources
## Related pages
- [[Page 1]]
- [[Page 2]]
## Gaps / uncertainty
State what the wiki does not yet know.
当想要问问题的时候,在 codex 中命令 LLM:
请按照 schema/query_prompt.md 回答我的问题:
- Lint
新建 schema/lint_prompt.md,写入 lint 的要求,这里展示一个例子:
# Lint Prompt
You are linting a Karpathy-style LLM Wiki.
## Goal
Inspect the structure and quality of `wiki/` without changing source materials.
## Rules
1. Do not modify `raw/`.
2. Do not delete any wiki page automatically.
3. Identify issues before fixing them.
4. If making safe fixes, only fix:
- broken internal links
- missing Related pages
- missing index entries
- obvious formatting inconsistencies
5. Do not rewrite factual content unless asked.
## Check these issues
### 1. Duplicate pages
Look for pages that cover the same topic, such as:
- RAG.md
- Retrieval Augmented Generation.md
- Retrieval-Augmented Generation.md
### 2. Missing Sources
Find pages without a `## Sources` section or with empty Sources.
### 3. Broken links
Find Obsidian links that point to missing pages.
### 4. Orphan pages
Find pages with no meaningful links to or from other pages.
### 5. Weak pages
Find pages that are too short, vague, or unsupported.
### 6. Naming consistency
Check whether page names are consistent:
- Use singular nouns for concepts.
- Use canonical paper titles for papers.
- Use full names for people.
### 7. Needs verification
Collect all claims marked as uncertain.
## Output format
## Summary
Overall health of the wiki.
## Critical issues
Issues that may mislead the user.
## Structural issues
Duplicates, broken links, orphan pages.
## Source issues
Pages missing citations or Sources.
## Suggested fixes
List safe fixes.
## Needs human review
List pages that should be checked manually.
当需要做 Lint 的时候,再指导 LLM:
请按照 schema/lint_prompt.md 对当前 wiki/ 做一次 Lint。
第一轮只报告问题,不要修改文件。
效果展示
- 目前喂入的 raw 数据
- Wiki 文件夹当中的内容

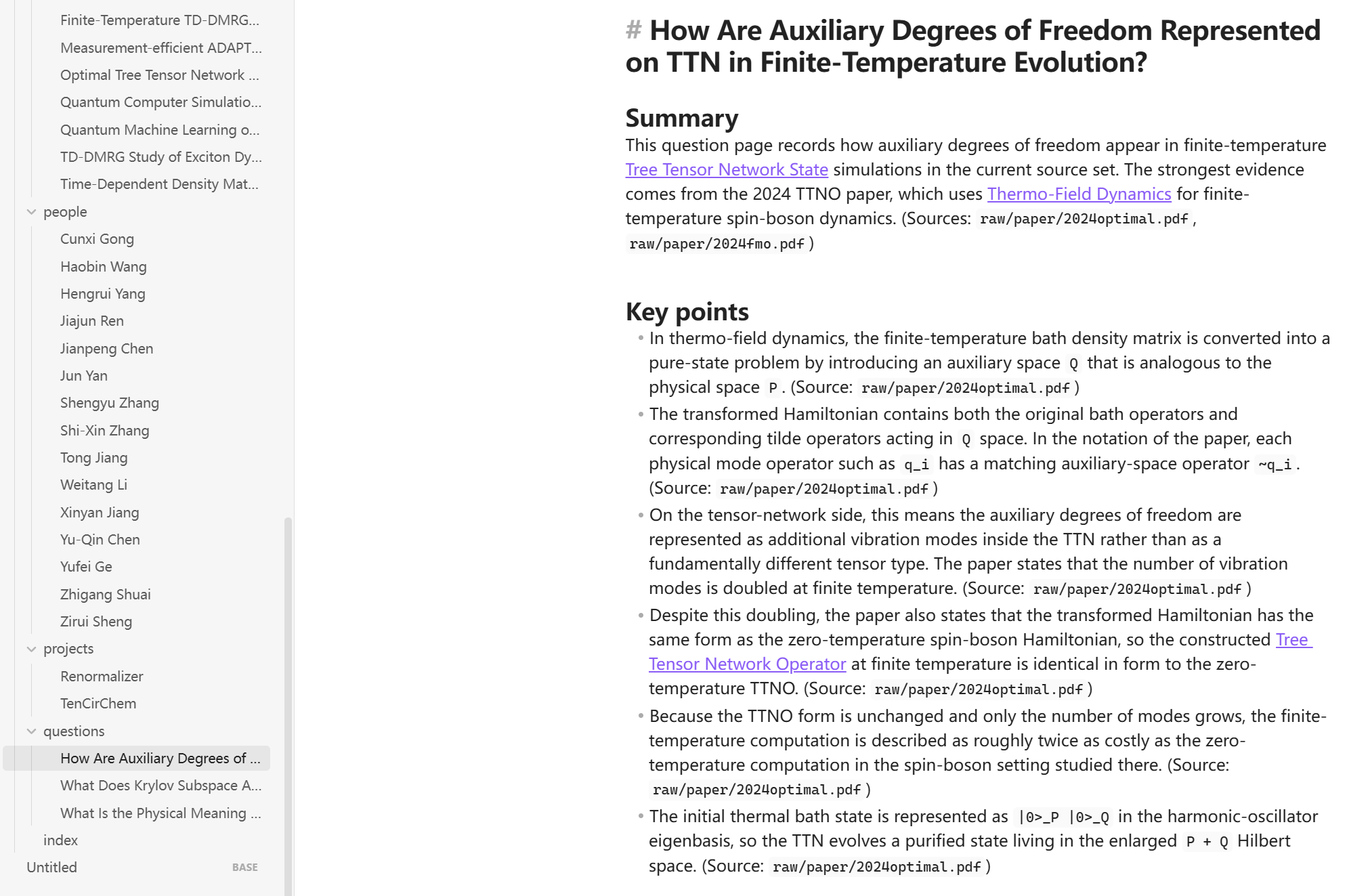
- 利用 LLM + Wiki
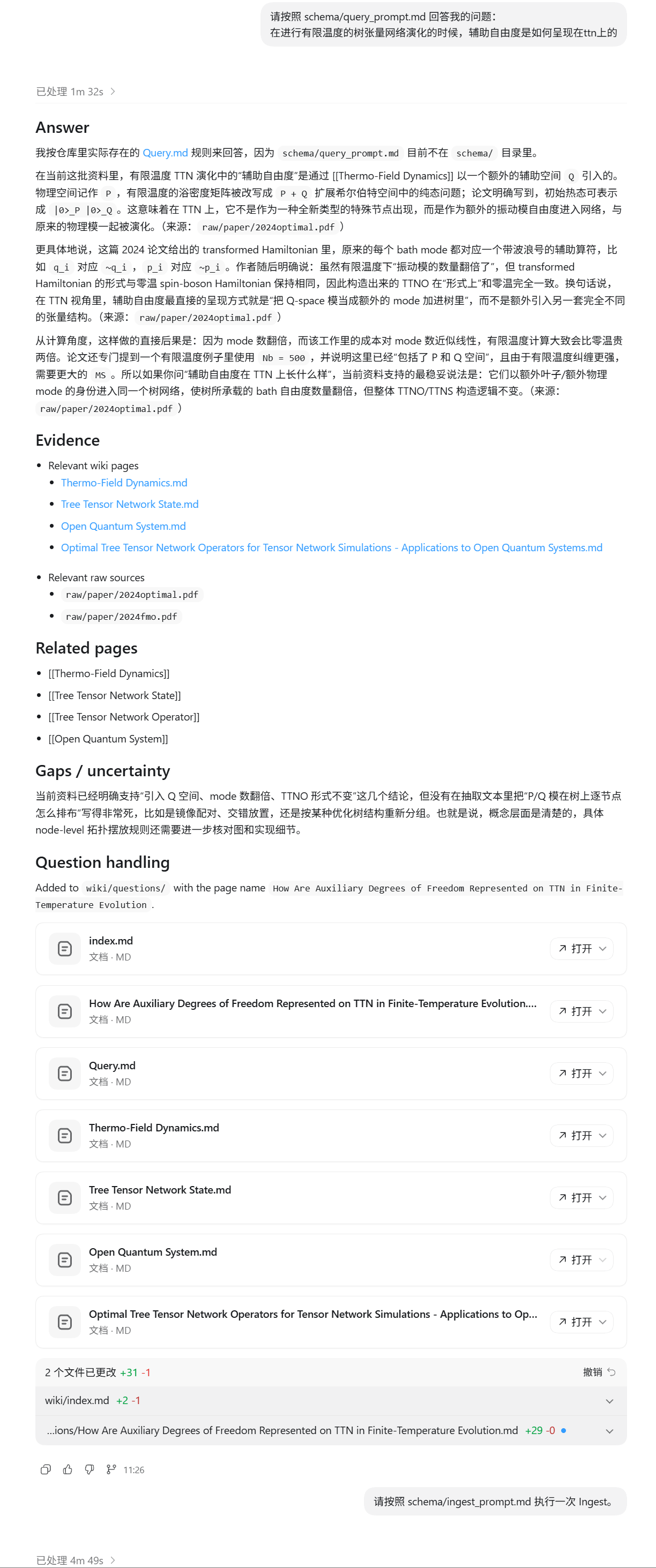
-
个人使用体会
-
确实很像 Wiki,可以用很简短的话来总结出较为全面的内容
- 对于一些深入的公式推导、图像理解,还达不到想要的效果
- 受限于已有知识,向外扩张的能力较弱
- LLM-Wiki 需要养,并且维护成本与实际使用需求会是一个 trade-off
- 实际使用而言,我将其作为一个保存 idea 的文献库使用,并且它的作用会是找寻文献(idea)之间的关联。不能苛求它一定要生成一个饱含细节且保证严谨的 Wiki,这对 LLM 和人的要求太高了,不值得花过多时间在这上面。至于细节与严谨,是需要人类(我)来精读文献(idea)来确认的。
- 在现在 vibe coding 的时代下,验证 idea 是 cheap 的,检验 idea,尤其是人来选择 idea 是昂贵的。从最高点来看,LLM Wiki 可以简化科研工作者对 idea 的选择;最低点来看,能够形成文献的成体系管理,搭建一个 LLM Wiki 也是值得的。
总结
LLM Wiki 是一套方法论。与 RAG 提问的时候才去翻原始资料不同,LLM Wiki 是让大模型一点点攒一个能一直用的 wiki 库——一堆互相链接起来的 Markdown 文件。
存入新资料的时候,大模型不只是建个索引等着以后搜,它会先读一遍,把关键信息抽出来,再揉到已经有的 wiki 里。知识只需要整理一次,之后一直维护更新。
人类的工作是整理来源,指导分析,提出好的问题,并思考这一切意味着什么。而 LLM 的工作则涵盖了其他所有方面。
适合:
- 垂直领域科研(攒你读过的好论文、专利、会议等)
- 单个项目研发(攒项目规范、设计文档、用户手册、需求文档等)
- 个人内容创作(攒素材、自己的作品、喜欢的作品等)
一些网上已经集成好的 skills
内容完备的:Gist 链接
内容简洁的:教程链接
可视化程度更好、更复杂一点:知乎文章
更大的长期 agent 平台,Hermes Agent,使用的 LLM-Wiki Skills:官方文档